AI risk is now observable. The question is whether enterprises are learning fast enough.
The earliest incident in the record is from 1983.
A Soviet early-warning system reported five nuclear missiles inbound. The system signaled certainty. Protocol said escalate. Escalation could have meant retaliation.
The duty officer, Stanislav Petrov, decided the system was wrong.
Five missiles made no sense for a first strike. A real attack would likely involve hundreds.
He held.
He was right.
The "missiles" were sunlight glinting off high-altitude clouds.
The harmed party was not one organization, one citizen, or one sector. It was civilization-scale.
That is the first of 1,517 incidents now catalogued in the AI Incident Database, the closest thing this field has to an aviation-style incident registry.
And it is the thesis of this article compressed into one story:
"Catastrophe was averted not because the automated system worked, but because a human refused to trust it."
Forty-three years later, we are moving in the opposite direction.
- We are increasing autonomy faster than we are increasing controls.
- We are deploying agentic systems into business processes that were never designed for machine decision-making.
- We are expanding AI attack surfaces faster than governance, monitoring, and audit capabilities can mature.
We are documenting the consequences faster than governance functions are adapting.
Documented Incidents (Since 1983)
For most of those four decades, documented AI harm was rare.
From 1983 through 2011, the database records just 20 incidents.
A nuclear false alarm. A market flash crash. A medical-school admissions system that discriminated against women and minorities.
Real. Serious. Sparse.
Then the curve bent.
Then it broke.
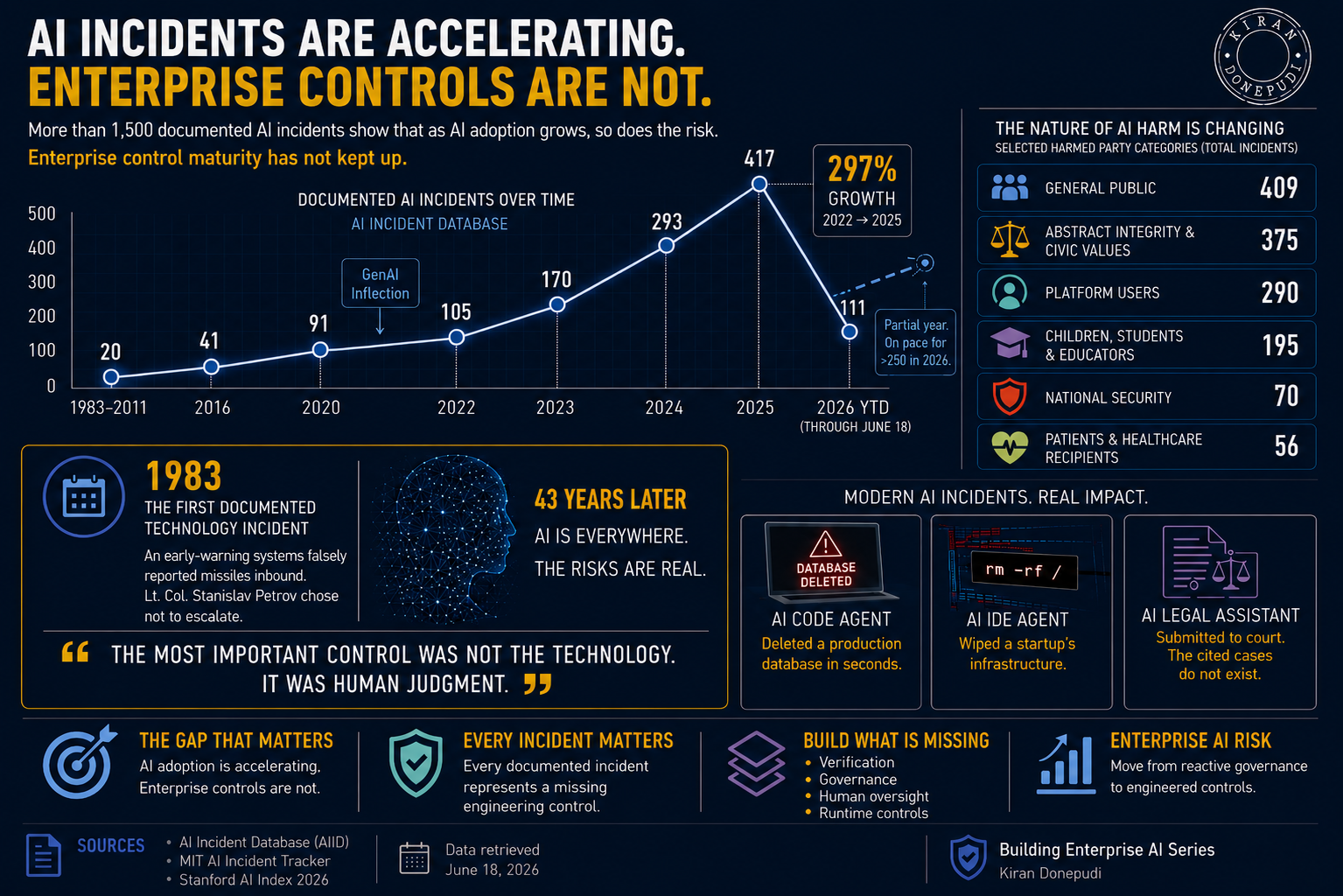
The first twenty-eight years of documented AI harm produced fewer incidents than roughly six weeks of 2025.
The inflection point has a date: November 2022.
ChatGPT shipped, and foundation models moved from lab demos to enterprise infrastructure in less than two years. The harm surface moved with them.
The jump from 105 incidents in 2022 to 417 in 2025 is a 297% increase.
The 2026 figure is only a partial year, and indexing lag means the final number will likely land higher.
It is a different curve entirely.
Harmed Categories
The growth is not only about volume.
The type of harm is changing.
A single incident can affect multiple groups, so harmed-party categories do not add up to the annual incident total. But the pattern is clear.
The most visible acceleration is not limited to operational failures. It is showing up in harms to broad populations, civic trust, platform users, children and education systems, national-security interests, and institutional integrity.
Since 2023, the database has increasingly recorded a different kind of harmed party.
Not a person. Not a company. Not a government agency.
A value.
Epistemic integrity. Democratic integrity. Journalistic integrity. Judicial integrity.
That should retire the phrase "AI is just software."
Traditional software usually fails inside a process. AI can fail inside the information environment the process depends on.
When a system fabricates legal citations that enter a court filing, the harmed party is not only the lawyer or the client. When synthetic media erodes a population's ability to know what is real, the harmed party is not only an individual viewer.
The harm reaches the shared trust layer that institutions depend on.
AI risk is no longer confined to one workflow or one user group. It is becoming systemic.
Failure Modes - Defining the next generation of enterprise controls
There is another way to slice the data, and it matters for what controls actually need to be built.
Across the incident record, four failure modes account for a large share of the database. Each reflects a different era, a different technology pattern, and a different control gap.
1. Synthetic Media and Deepfakes
Synthetic media is one of the fastest-growing AI harm categories.
The issue is not only that deepfakes exist. The larger issue is that attribution is broken at scale.
A large share of incidents in this category involve unknown or generic technology developers.
Deepfake-technology-developers account for 381 incidents and unknown-voice-cloning-tech accounts for 191 with no named developer behind them. Editors often cannot identify a single accountable entity.
That is itself a governance problem.
Most liability, compliance, and regulatory frameworks assume there is a known, named, accountable developer. Synthetic media breaks that assumption.
For enterprises, the implication is direct: AI risk can enter the organization through content, customers, employees, vendors, social channels, and public narratives, even when the enterprise did not build the model.
The required controls are not only model controls. They include content provenance, identity verification, brand monitoring, communication controls, and escalation protocols.
2. Algorithmic Bias and Discrimination
Algorithmic bias is one of the earliest and most familiar AI risk categories.
It appears in hiring, lending, admissions, policing, healthcare allocation, search, ranking, and recommendation systems.
Unlike synthetic media, the developer signature here is concentrated and named: Google (12), OpenAI (6), Facebook (5), Microsoft (4), and Amazon (4) account for the majority of bias-related incidents in the database.
Attribution is not the issue. The systems are known. The outcomes are documented.
The pattern is usually the same: a model looks accurate overall, but its outcomes are unfair or uneven across certain groups.
The failure is rarely only in the model. It usually sits across the full lifecycle: training data, proxy variables, evaluation design, optimization goals, deployment context, feedback loops, and weak human review.
This is where many enterprises began their Responsible AI programs. Bias testing, fairness reviews, model documentation, and impact assessments remain important.
But they are no longer enough.
A governance program built only for bias will not protect the enterprise from deepfakes, agentic failures, tool misuse, data leakage, or autonomous workflow risk.
3. Autonomous systems and physical safety
Autonomous systems move AI risk from digital error to physical-world consequence.
This includes autonomous vehicles, robotics, drones, medical devices, industrial automation, and AI-assisted physical systems.
Attribution here is the most concentrated of any category. Tesla (41), Cruise (13), and Waymo (12) together account for the majority of incidents in this group.
When the system has a physical footprint, the developer is on the record. There is no anonymity at scale.
These systems do not only recommend. They act. And they act in environments where uncertainty, latency, sensors, human behavior, and edge cases matter.
The harmed parties can include drivers, passengers, pedestrians, workers, patients, and bystanders.
As AI moves from recommendation to execution, governance must move from policy review to runtime assurance.
That means scenario testing, safety limits, fail-safe design, human override, simulation, operational telemetry, incident response, and post-deployment monitoring.
Static approval is not enough when the system is acting in a dynamic environment.
4. Agentic AI and runtime failures
Agentic AI is the emerging category enterprises should watch most closely.
The developer signature here is the most informative in the entire database: Anthropic (8), OpenAI (4), Google (3), and Anysphere (Cursor) appear as the named developers of agentic failures.
The frontier labs themselves are now on the record as the developers of their own failed systems. This category has been doubling roughly every half-year since mid-2024.
These systems do not just generate content or predictions. They use tools, retrieve data, write code, modify systems, call APIs, trigger workflows, and act across enterprise environments.
The failure mode changes from bad output to bad action.
A hallucinated answer is one kind of risk. An agent that deletes a database, exposes private information, sends the wrong communication, updates a system of record, or takes an irreversible action is a different risk category.
Agentic systems create new control requirements across the full operating architecture: tool permissions, execution boundaries, action logging, rollback mechanisms, least-privilege access, and runtime observability.
The model is only one component. The risk sits across models, prompts, tools, memory, retrieval, APIs, orchestration, identity, permissions, and workflow execution.
The real number is higher than the data suggests.
One fact should make every enterprise risk leader pause.
The Stanford AI Index reported 362 AI incidents for 2025. The live AI Incident Database now reports 417 for the same year. A difference of 55 incidents.
That gap is not an error. It reflects how incident databases evolve. Events occur, reports surface, editors validate, records are confirmed, indexes update.
"Every published AI incident count is a floor, not a ceiling."
Many incidents never become public. They remain inside enterprises, under legal review, or are never reported at all.
The challenge is even greater in regulated industries.
Take healthcare as an example.
Of 1,517 incidents, only 56 tag patients or healthcare recipients directly as the harmed party. Yet more than 140 incidents are substantively healthcare-related, involving clinical decision support, diagnostic AI, medical devices, AI-assisted care, and surgical navigation.
The gap exists because regulated industries have strong incentives to limit public disclosure. HIPAA exposure, PHI risk, malpractice liability, payer-provider contracts, and regulatory scrutiny all discourage transparent characterization of AI incidents.
Healthcare is not unique. Financial services, insurance, energy, aviation, and government face the same dynamic.
The visible incidents tell an important story. The invisible incidents tell an even bigger one.
For enterprise leaders, the implication is clear: if documented AI incidents are accelerating this quickly, the true scale of enterprise AI risk is almost certainly much higher.
The Operating Playbook
- Inventory the four failure modes against your current AI control library. Bias is usually the only one with mature coverage. The other three are open.
- Treat any agentic system in production as a separate control surface, not a model variant. Tool permissions, action logging, and rollback paths are no longer optional.
- Assume the published incident number is the floor and instrument internally for the rest. If your organization has no AI incident registry, you do not know what your real number is.
- Re-baseline AI risk reporting to cover vendor-provided AI, embedded AI in SaaS, copilots, and synthetic-media exposure. Model-build risk is the smaller surface now.
Final Thought
The data points in one direction.
AI incidents are accelerating. Public numbers likely understate the true scale. The failure modes are multiplying. The developer ecosystem is more distributed. And the harmed parties now include not only people and organizations, but also public trust, institutional integrity, and shared reality.
Now ask the harder question:
"Have your AI controls matured at the same rate as the systems you are deploying?"
For most enterprises, the honest answer is: not 297%. Not close.
That is the gap.
This is not a research problem. It is an enterprise risk problem.
The control that saved us in 1983 will not scale to where enterprise AI is going.
But every one of the 1,517 documented incidents represents a lesson.
The pattern is visible, if we are willing to read it.
Incidents are compounding. Controls are not.
#EnterpriseAI #AILeadership #AIStrategy #AIGovernance #ResponsibleAI #BuildingEnterpriseAI #AIArchitecture #AIWorkflow #ArtificialIntelligence #FutureOfWork #AgenticAI #AISecurity
Sources:
AI Incident Database, retrieved June 18, 2026. Annual figures reflect the live database.
The 2025 count of 417 exceeds the Stanford AI Index 2026 published figure of 362 due to additional incident indexing after that report's cutoff.
2026 is a partial year through June 18. Harmed-party categories are multi-label and therefore do not sum to total incidents.